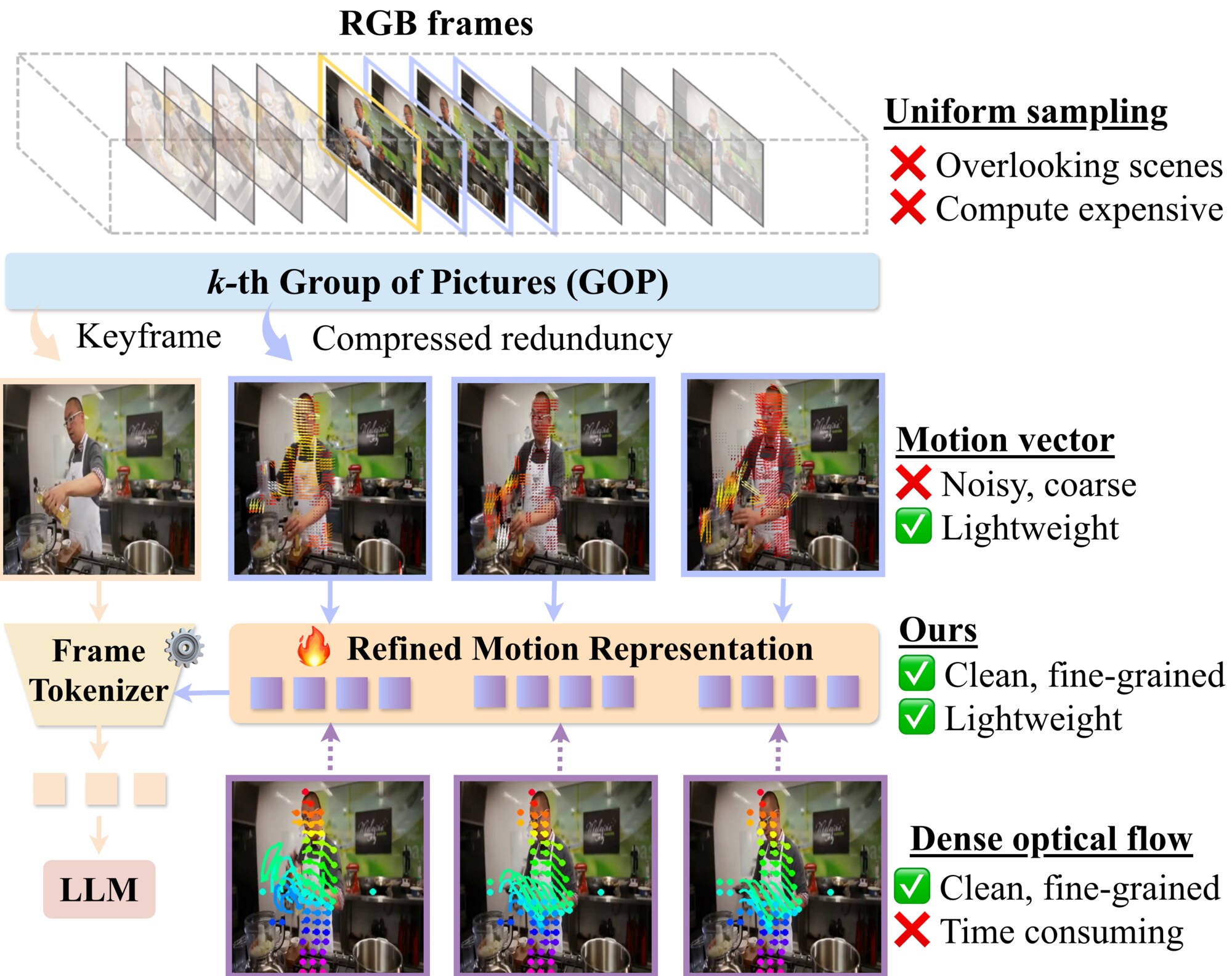
ReMoRa tackles long-form video understanding with multimodal LLMs by operating directly on compressed video streams. Instead of decoding dense RGB sequences, we keep scene-adaptive I-frames for appearance while encoding temporal dynamics as codec motion vectors that act as a lightweight proxy for optical flow. A Refined Motion Representation (RMR) module denoises and densifies those coarse motions, and a Hierarchical Motion State Space (HMSS) module performs linear-time reasoning across group-of-picture hierarchies. This codec-aware pipeline scales to hour-long clips, improves temporal fidelity, and removes redundant computation. ReMoRa consistently surpasses contemporaneous video MLLMs, reaching 60.8 on LongVideoBench, 84.2 on NExT-QA, 72.1 on MLVU, and an average score of 69.8.
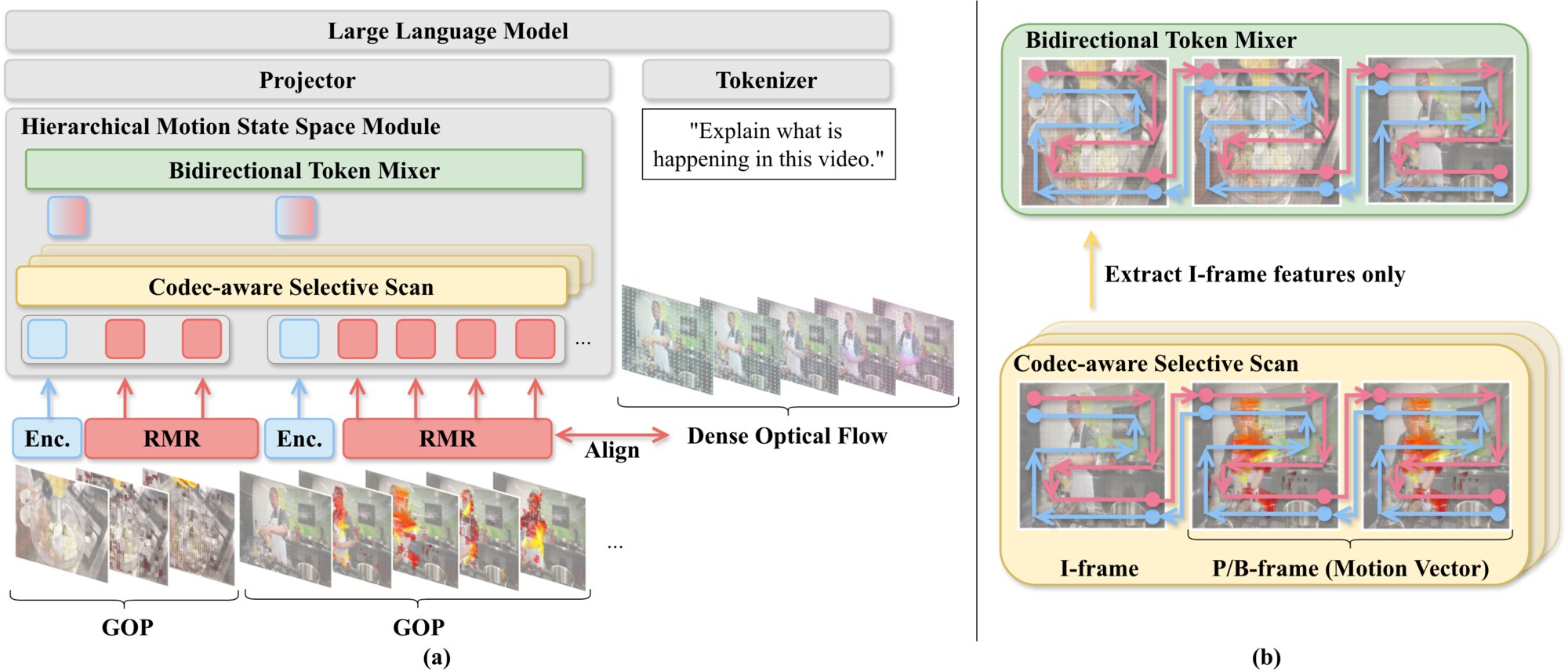
Each video is decomposed into group of picture (GOP) chunks. I-frames preserve appearance via a SigLIP encoder, while block-based motion vectors from P/B frames feed the RMR module, which denoises, densifies, and aligns motion vectors with dense optical flow. The HMSS module then performs codec-aware selective scans to summarize every GOP locally before propagating linear-time state transitions across the entire clip.
I-frames arrive as codec-designated keyframes, so every GOP inherits high-fidelity anchors that latch onto abrupt scene cuts the instant they occur. P/B-frame block motion vectors offer a lightweight pseudo optical flow proxy, but their coarse, noisy nature motivates our RMR module, which aligns these motion cues with dense optical flow supervision before downstream processing.












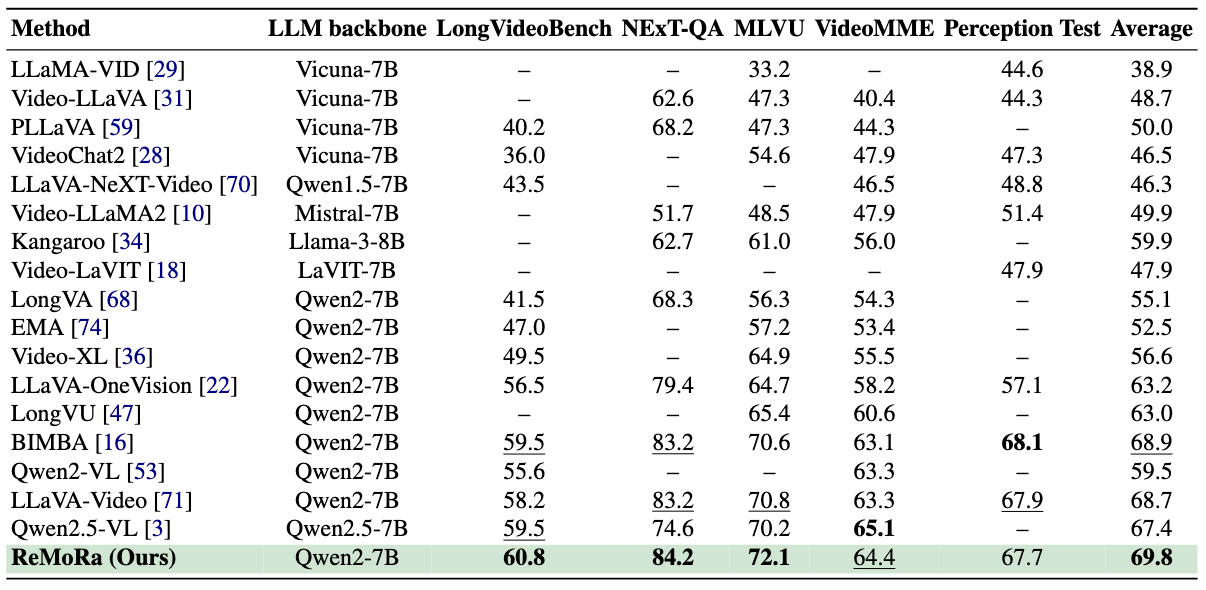
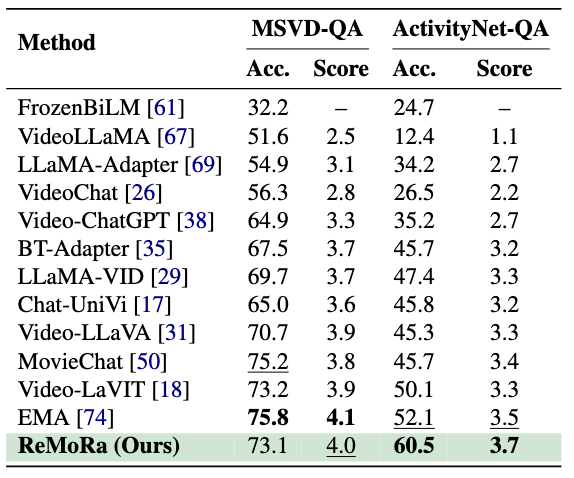
ReMoRa attains 60.8 on LongVideoBench, 84.2 on NExT-QA, 72.1 on MLVU, 64.4 on VideoMME, and 67.7 on Perception Test, yielding the top average score of 69.8 across six long-video benchmarks. For open-ended VideoQA, the model sets a new best of 60.5/3.7 Accuracy/Score on ActivityNet-QA and delivers 73.1/4.0 on MSVD-QA.

On NExT-QA, ReMoRa tracks subtle human-object interactions such as “slide down the rail and check pants” or “dog retrieves the thrown object” by leveraging refined motion fields, whereas RGB-only baselines hallucinate abrupt actions. The refined motion cues keep temporal ordering intact even when question cues refer to events several seconds apart.
@inproceedings{yashima2026remora,
title={ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding},
author={Yashima, Daichi and Kurita, Shuhei and Oda, Yusuke and Sugiura, Komei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026},
}